François Dumont
Data Analyst - Ingénieur
Data Analyst - Ingénieur






Transformer les données en informations exploitables
Passionné par l'analyse de données et la résolution de problèmes, j'aide les entreprises à prendre des décisions éclairées en transformant des données brutes en informations significatives.
De l'amélioration de la qualité à la stratégie fondée sur les données
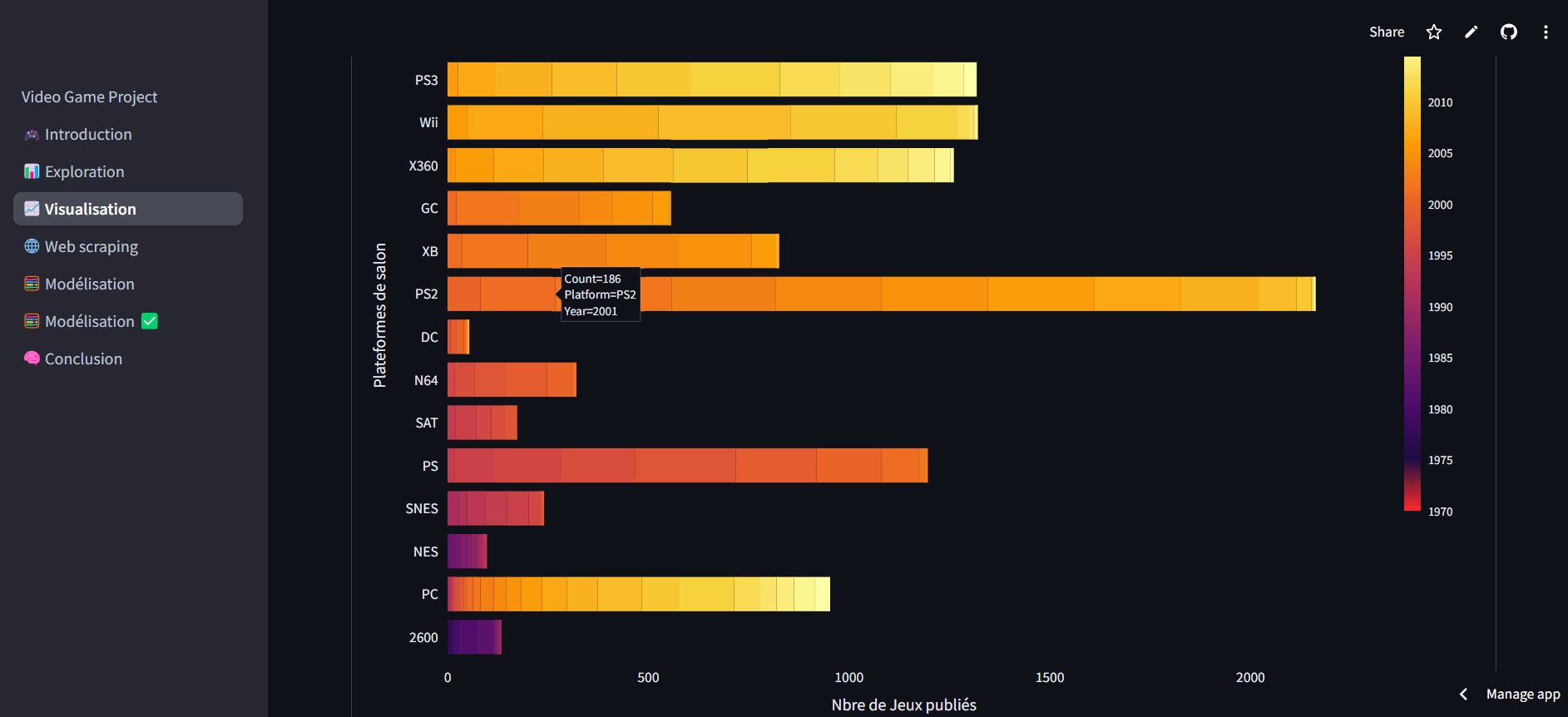
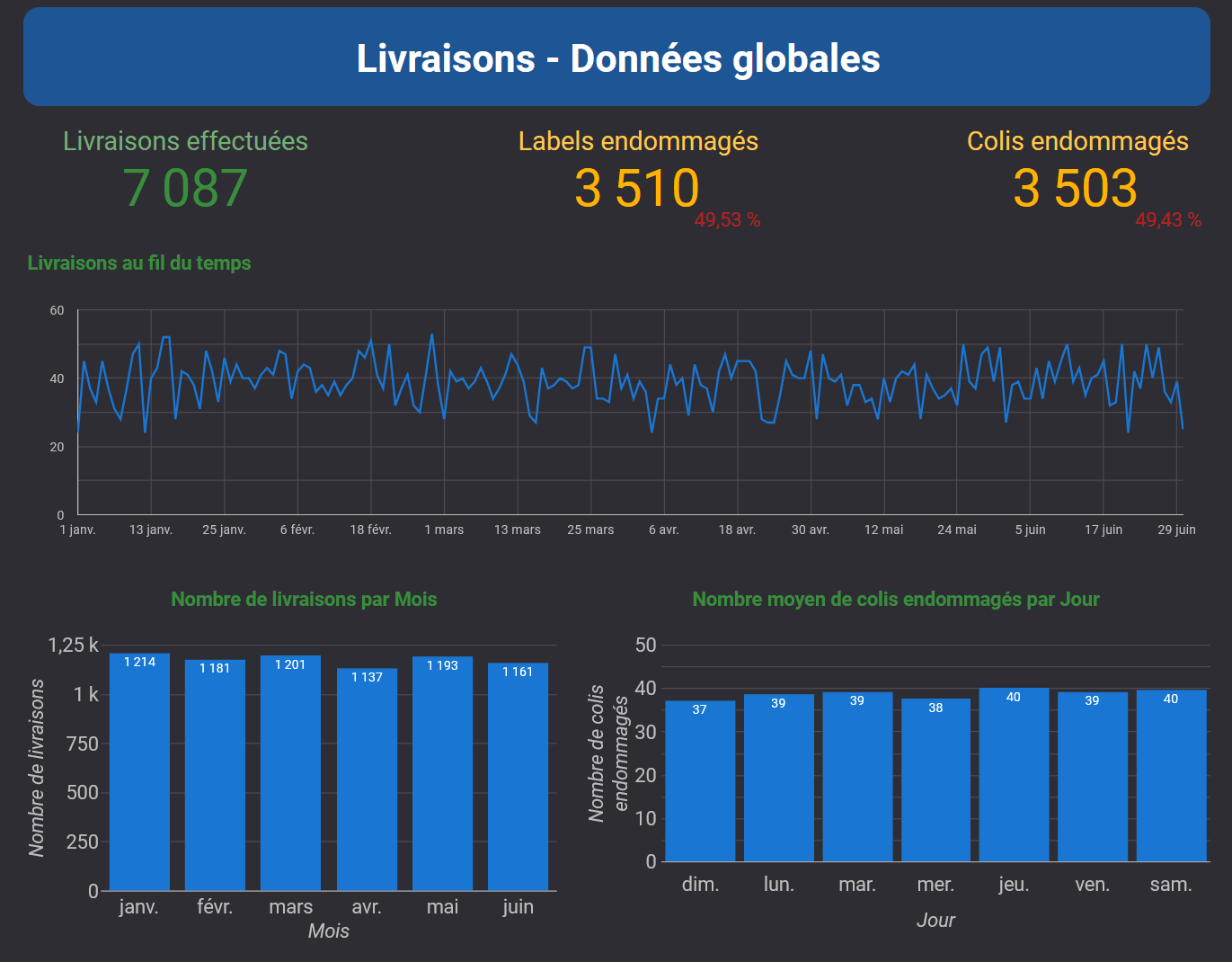
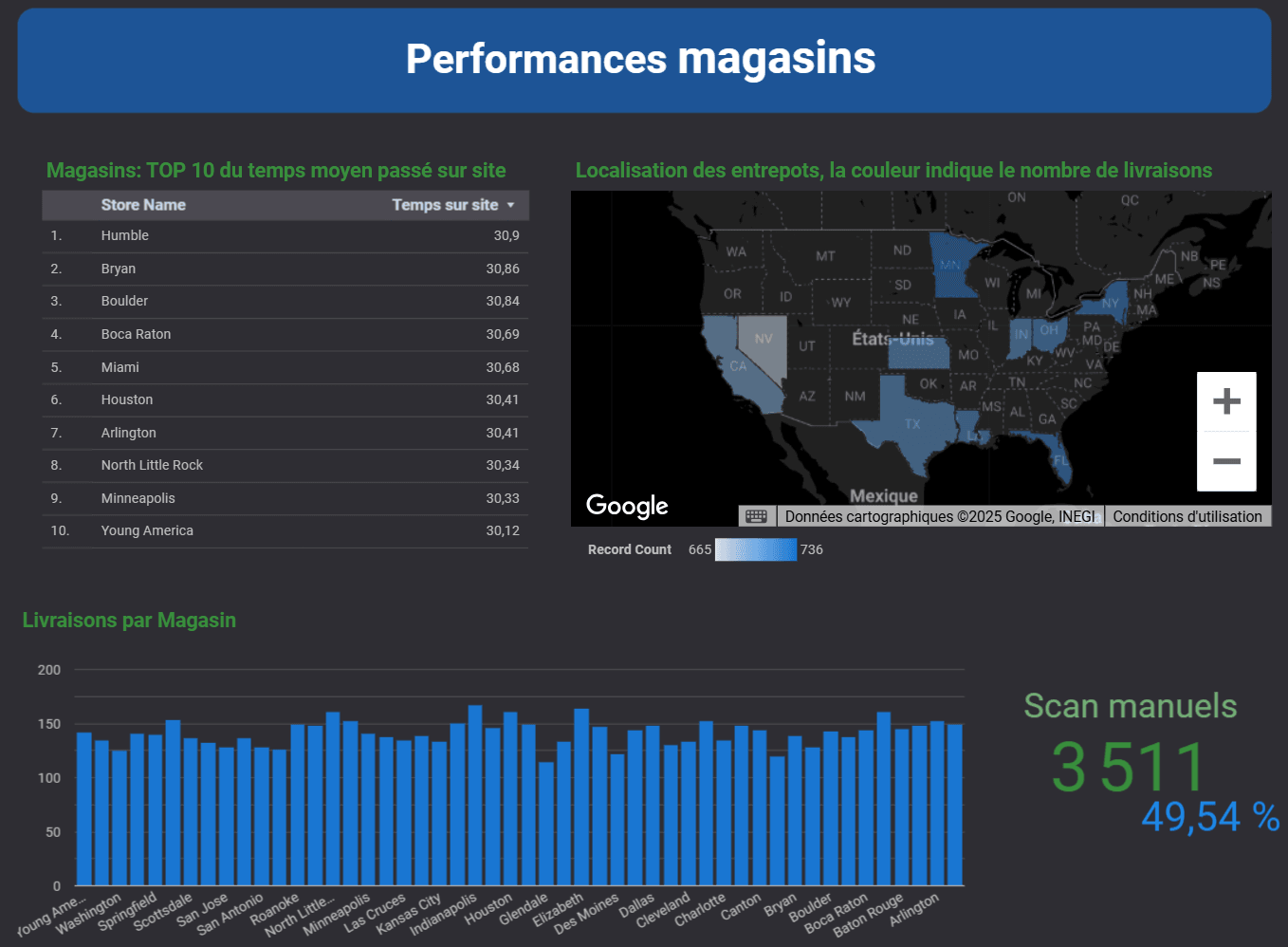
Dans l'industrie de l'électronique automobile, j'ai mené des analyses de données approfondies et développé des visualisations claires qui ont amélioré l'efficacité des processus et la qualité des produits. Mon travail a joué un rôle clé dans l'affinement de la détection des anomalies et l'optimisation des flux de travail.
Élargir mes connaissances
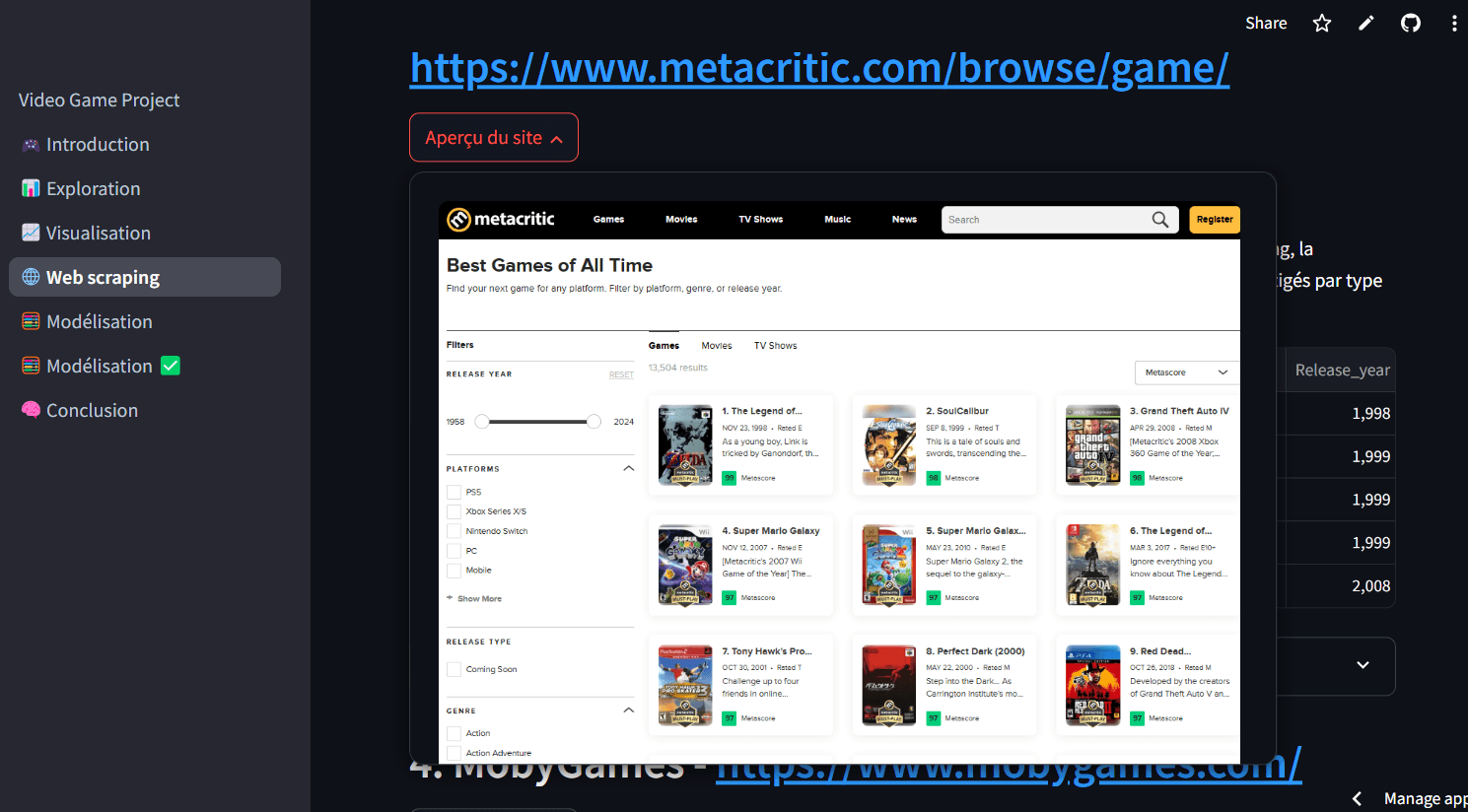
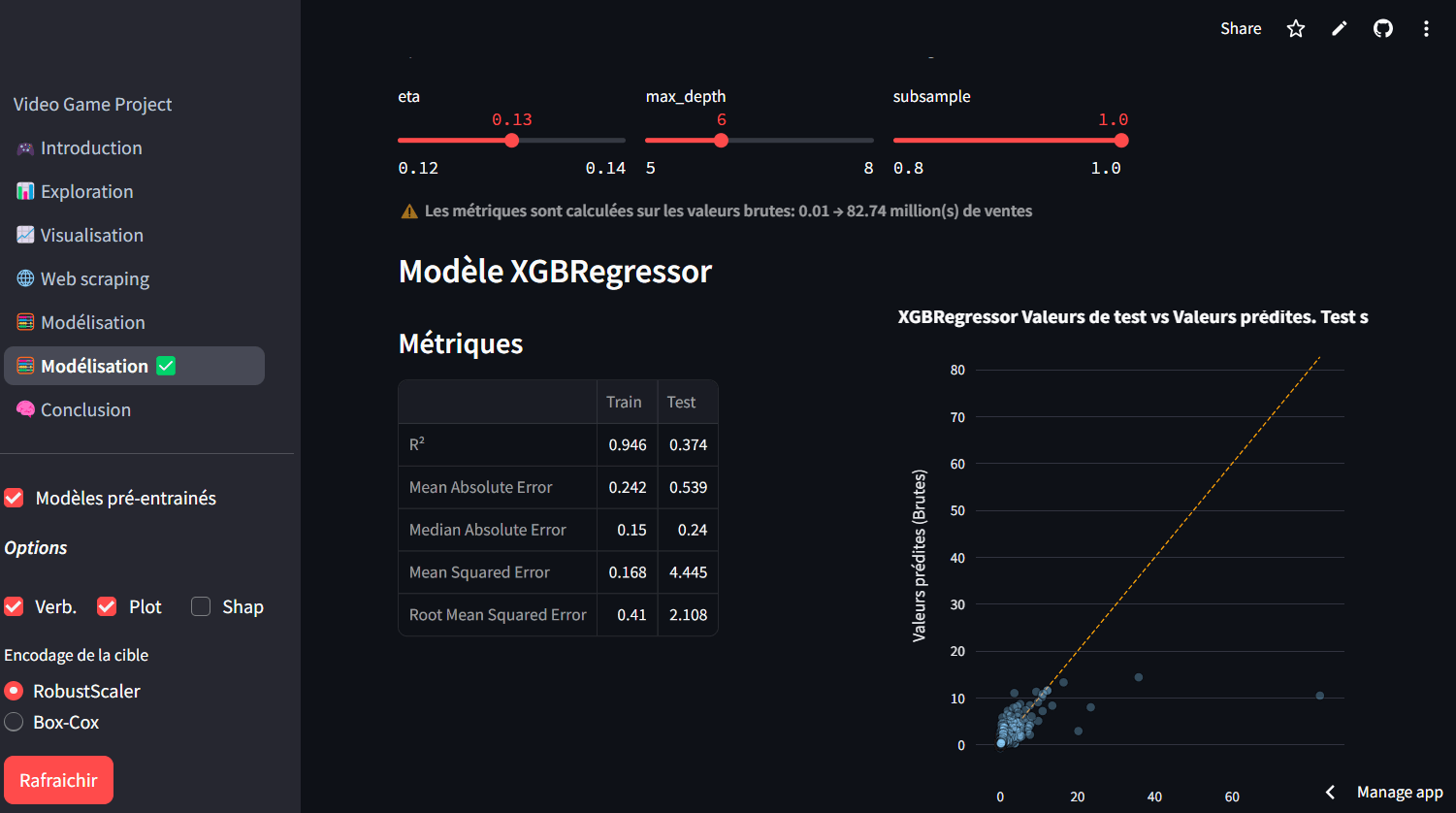
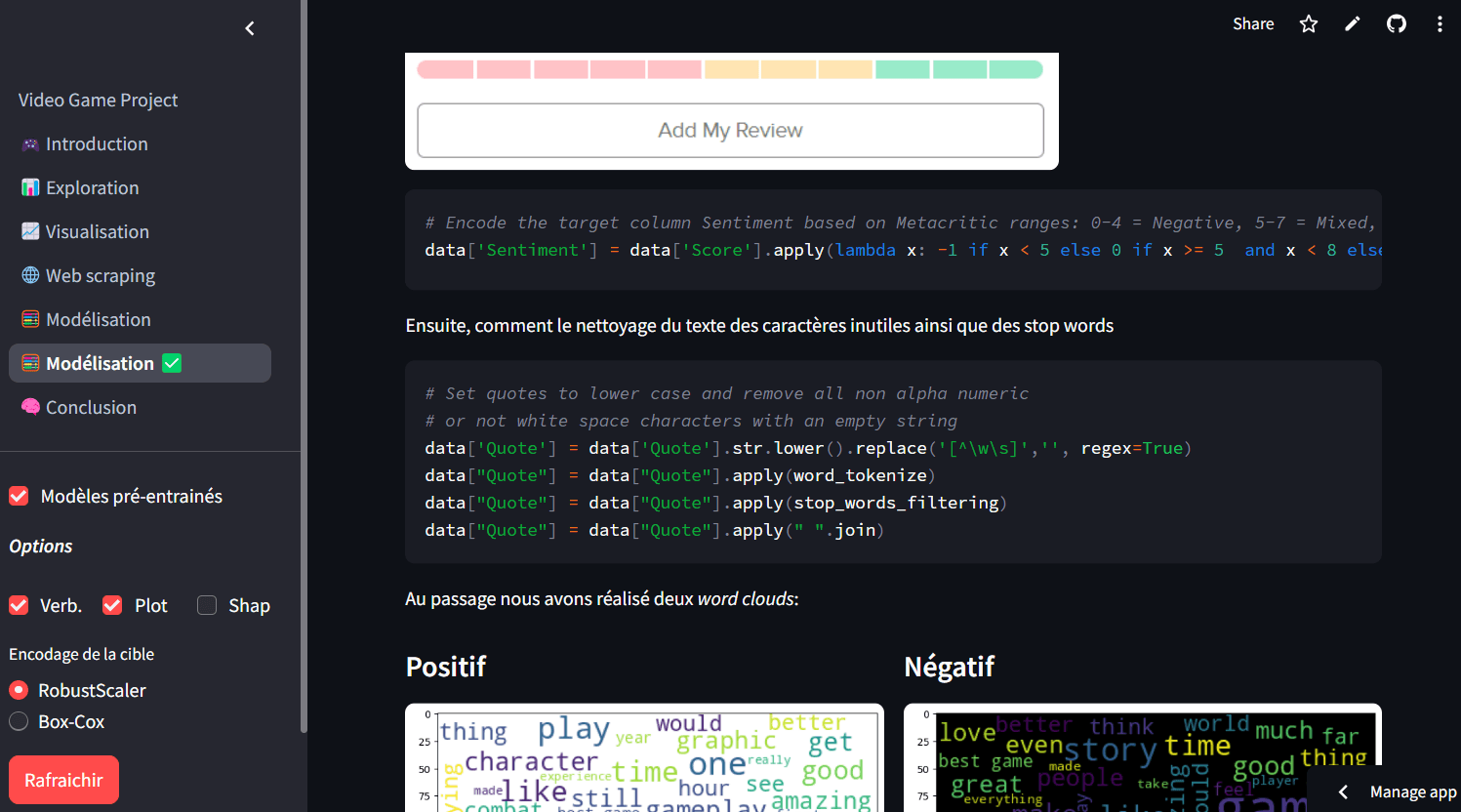
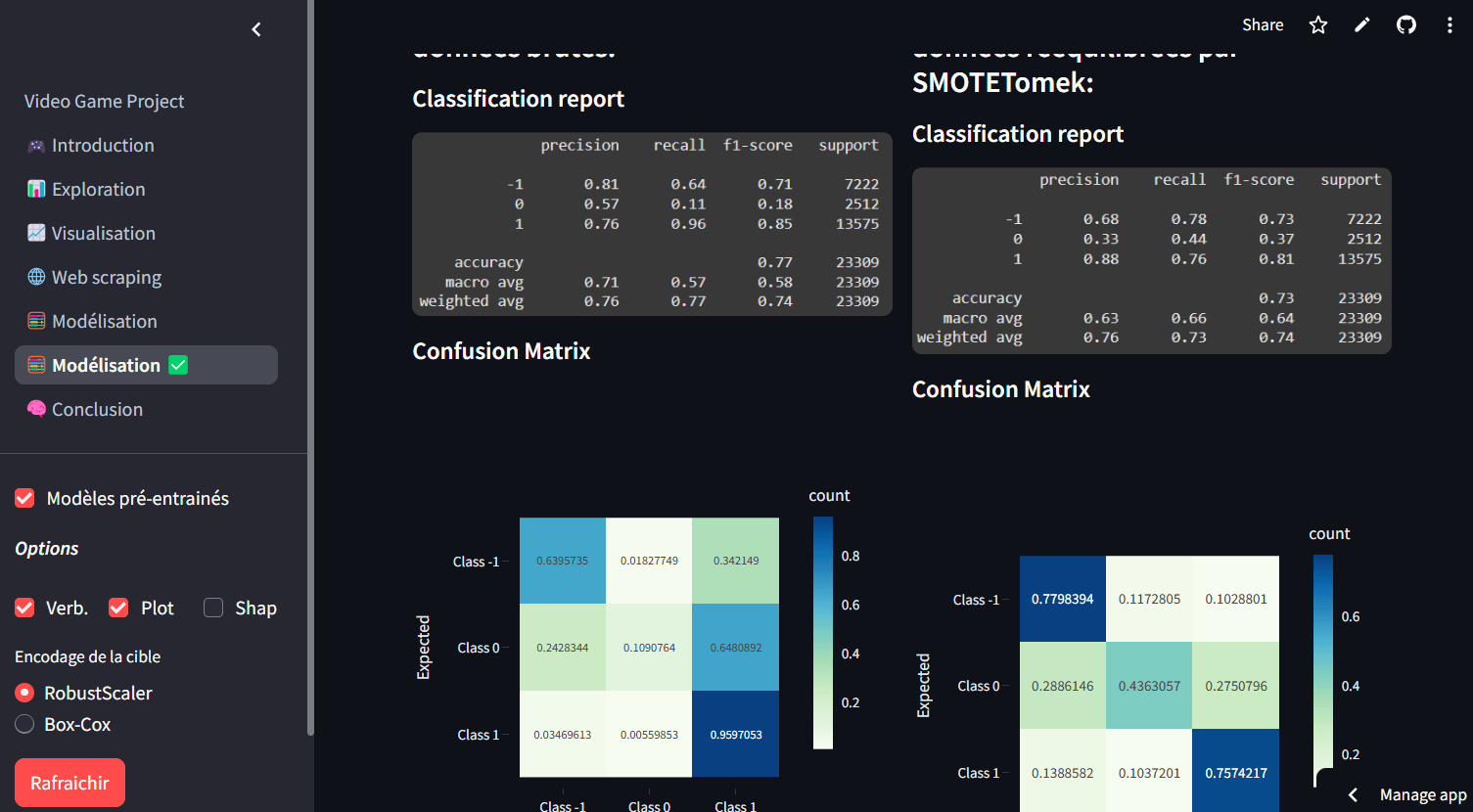
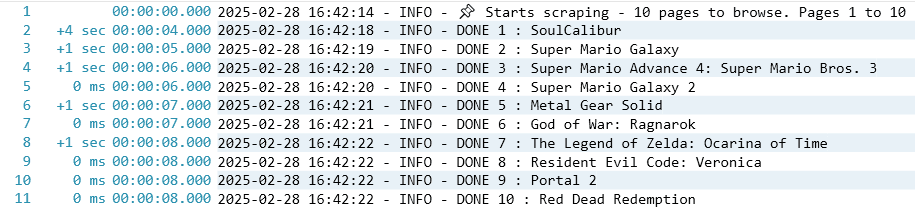
Pour renforcer mes compétences, j'ai suivi un programme intensif de formation d'analyste de données, où j'ai approfondi mes connaissances en Business Intelligence, Machine Learning et Text Mining, tout en affinant mon expertise en SQL, Python et visualisation de données.
En quête de nouveaux défis
Je suis impatient d'appliquer mon expertise dans un environnement dynamique où la prise de décision fondée sur les données est essentielle. Je suis particulièrement intéressé par l'utilisation de l'analyse pour stimuler la performance de l'entreprise et l'excellence opérationnelle.
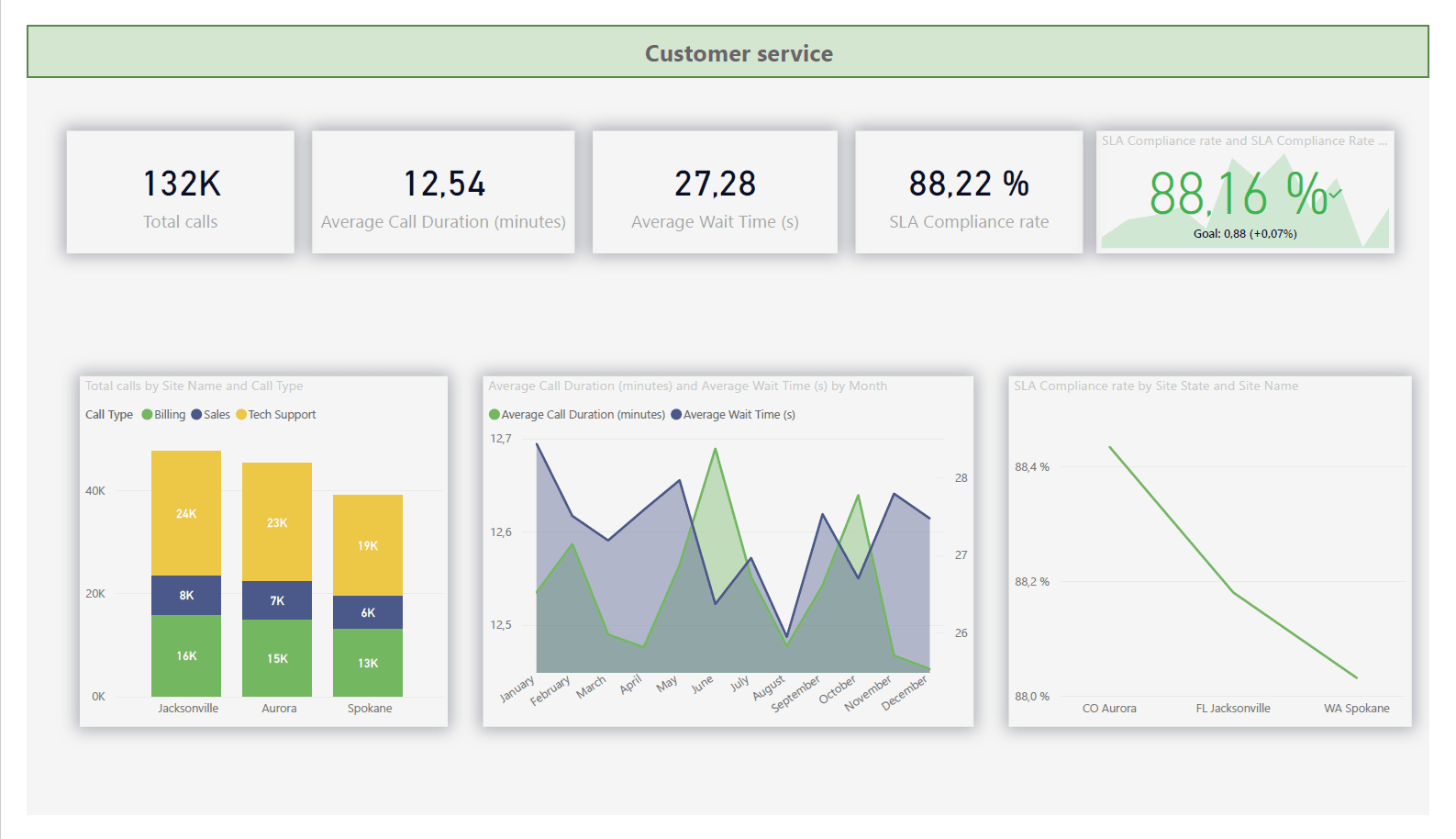
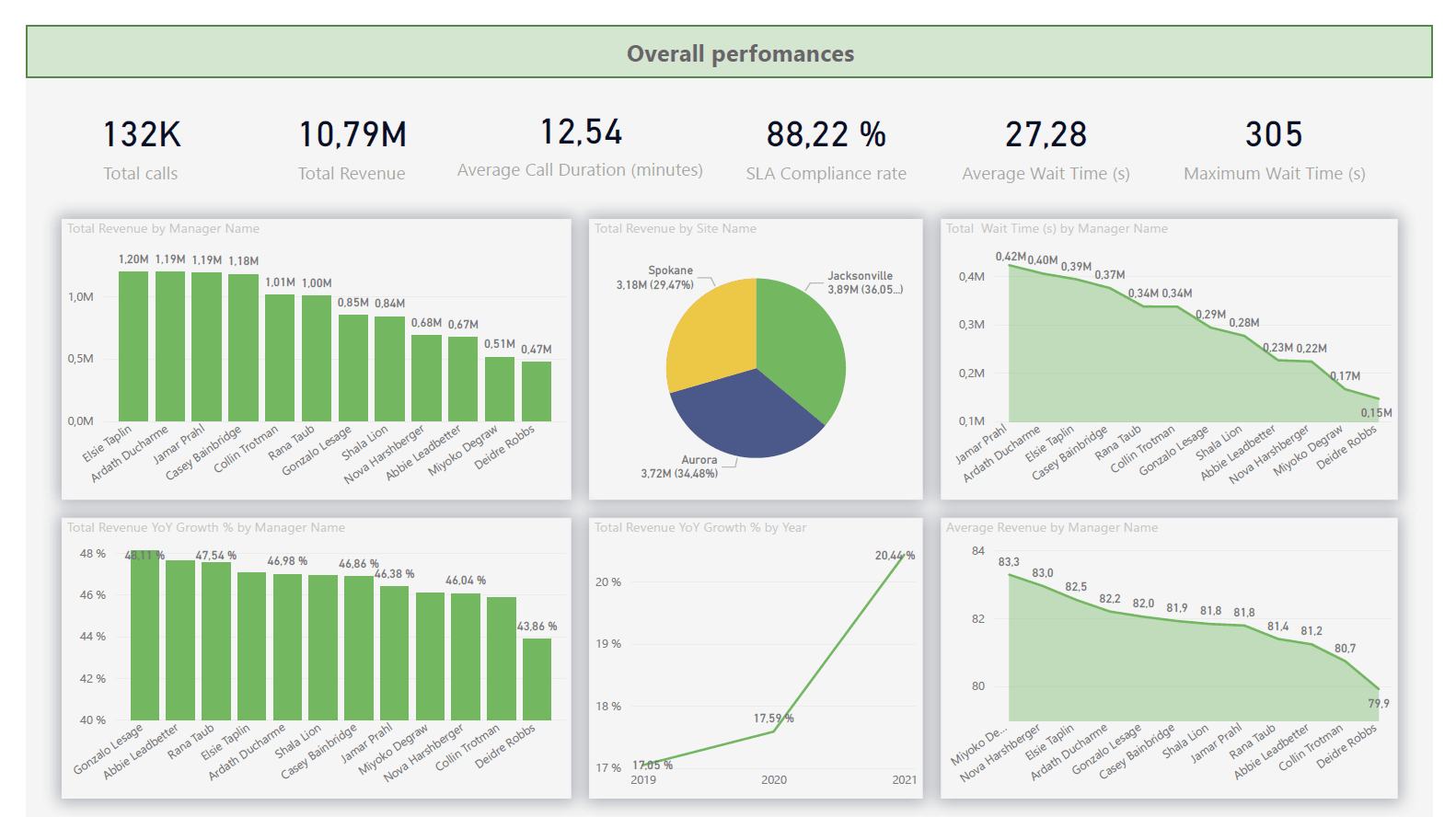
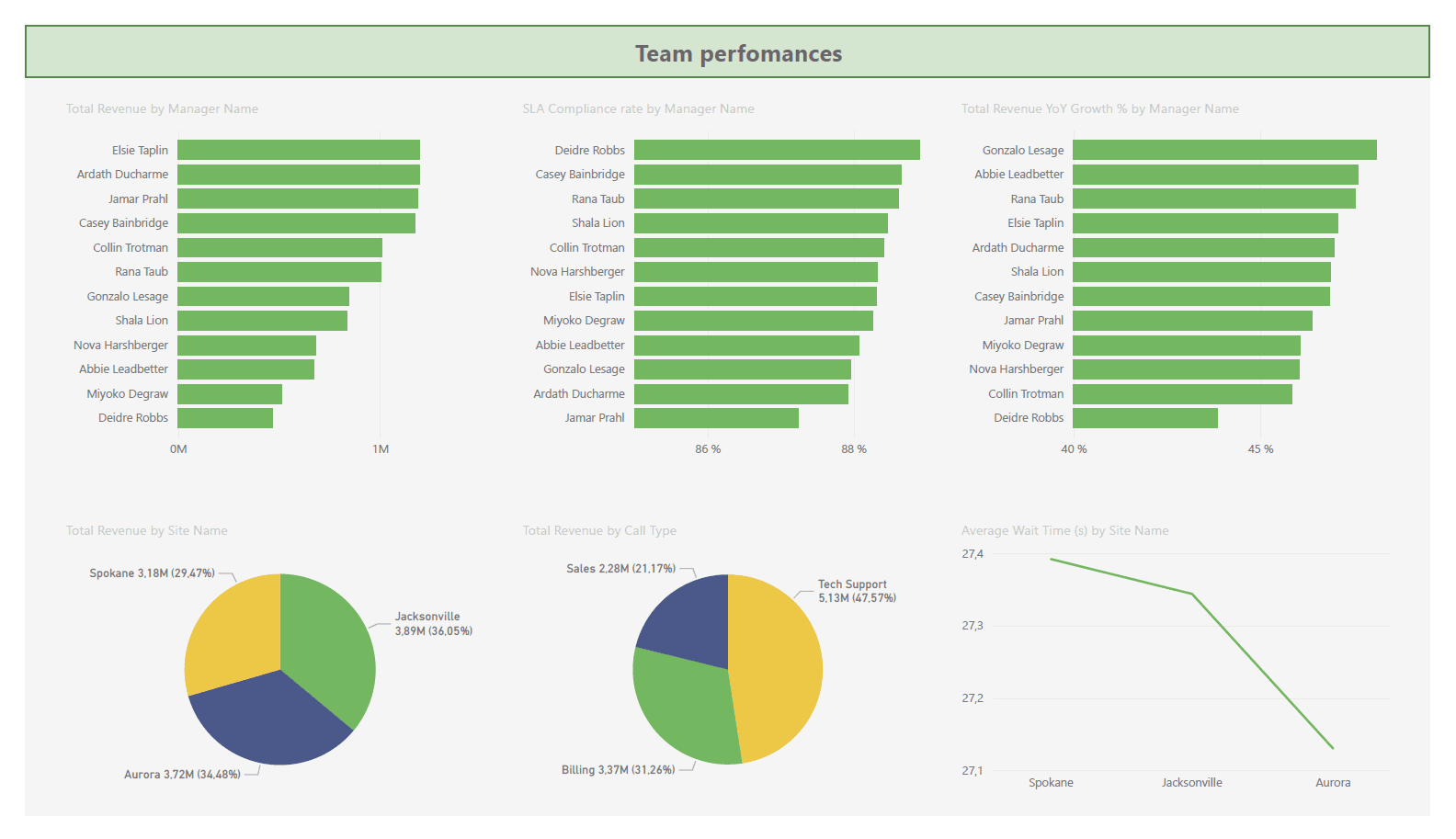
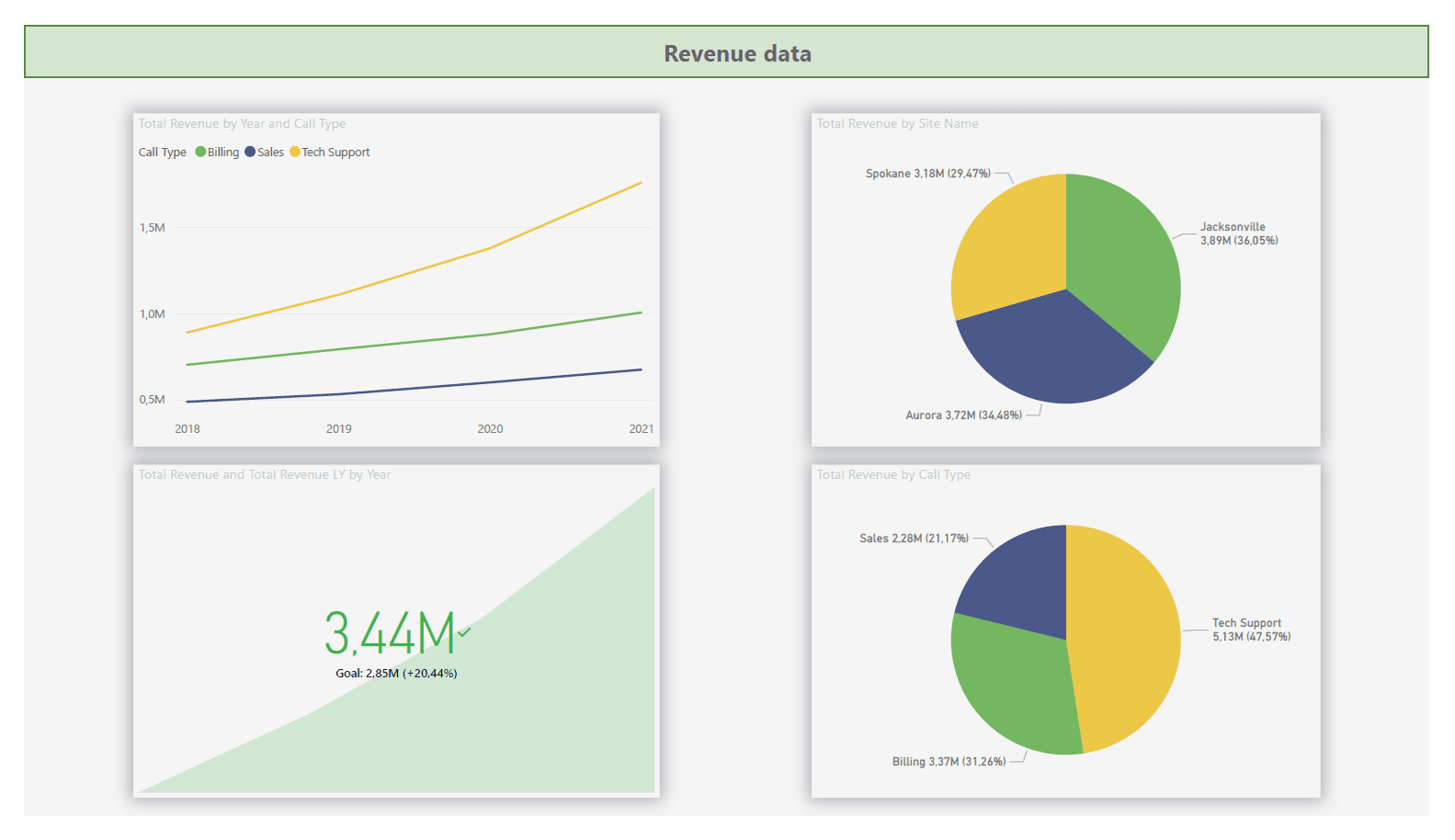
 .
.